
In the "old days" of 2024, billing for Large Language Models (LLMs) was simple: you paid for what you sent (Input) and what you got back (Output). In 2025, the rise of Reasoning Models (like OpenAI o1, DeepSeek-R1, and Google Gemini 2.0 Thinking) has introduced a third, often invisible billing dimension: Reasoning Tokens.
This article deconstructs the new anatomy of an inference call and explains why your "short answer" might be costing you a fortune.
The New Billing Equation
Traditional LLM billing looked like this:
Cost=(Input Tokens×P in )+(Output Tokens×P out )
The 2025 equation for reasoning models adds a critical component:
Cost=(Input×P in )+(Visible Output×P out )+(Reasoning Tokens×P reasoning )
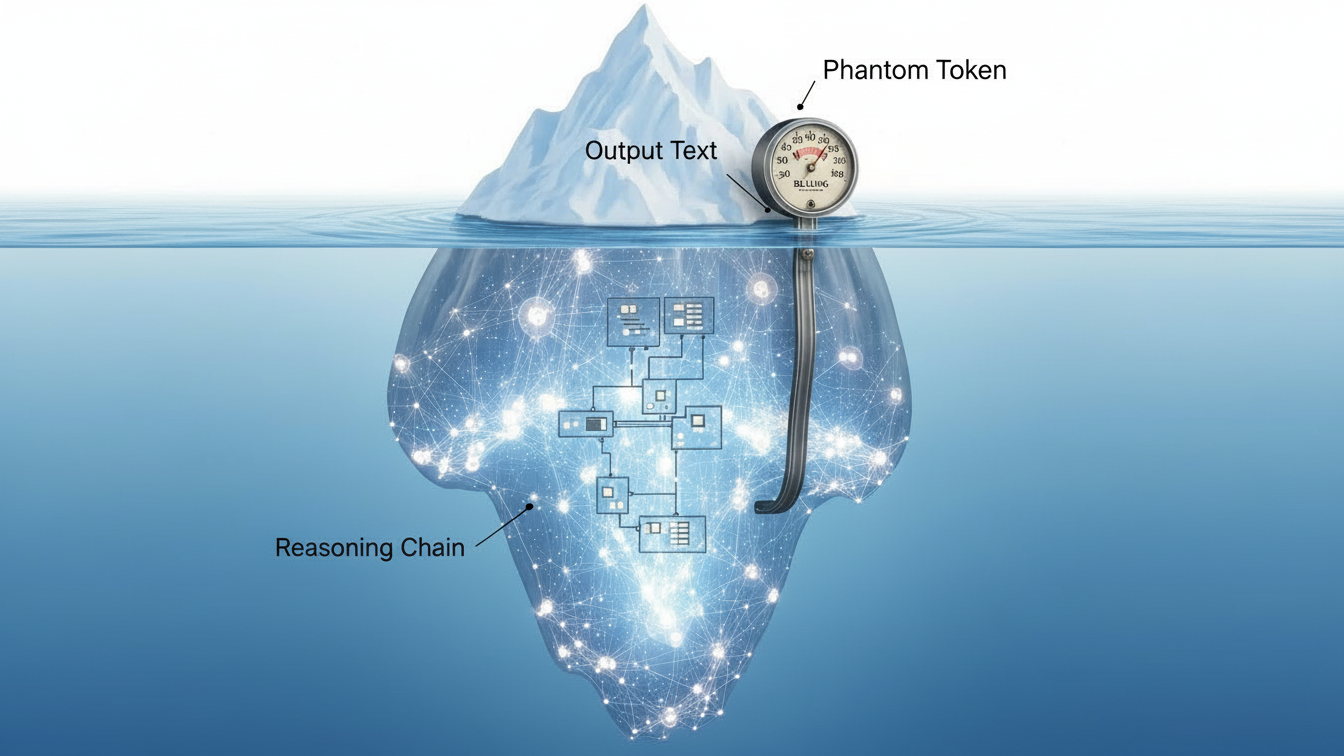
The "Phantom" Tokens
Reasoning tokens are generated by the model to "think through" a problem using Chain-of-Thought (CoT) logic. Crucially, these tokens are often discarded before the final response is sent to the user, but they are billed as output tokens.
Case Study: The "Simple" Math Problem
User Prompt: "Solve this differential equation..." (50 tokens)
Model Process:
Step 1 (Internal): Decomposes equation. (500 tokens)
Step 2 (Internal): Attempts method A, fails. (1,000 tokens)
Step 3 (Internal): Backtracks, tries method B, succeeds. (2,000 tokens)
Final Answer: "The solution is $x=5$." (10 tokens)
The Billable Event: You see 60 tokens (50 in + 10 out). You are billed for 3,560 tokens.
Managing Reasoning Depth
API providers have introduced parameters to control this hidden cost.
reasoning_effort(OpenAI/Azure):low: Forces the model to take fewer logical steps. Good for quick validations.high: Allows deep exploration. Essential for coding or scientific proofs but can spike costs by 10x.
max_reasoning_tokens(DeepSeek/Anthropic): A hard cap on the internal scratchpad. If the model hits this limit without finding an answer, it returns its best guess or an error.
Architectural Best Practice: The "Verifier" Pattern
To optimize costs, avoid asking the reasoning model to generate simple text. Use it only to verify or structure complex logic.
Expensive: Ask o1 to "Write a blog post about quantum physics." (It will overthink the structure, tone, and facts).
Efficient: Ask o1 to "Create a detailed outline and fact-list for a blog post about quantum physics." Then, pass that outline to a cheaper model (GPT-4o or Llama 3.2) to do the actual writing.
Conclusion: In 2025, engineering leaders must audit their logs not just for response length, but for total generation length. If you aren't tracking reasoning tokens, your unit economics are wrong.
All in One Place
Atler Pilot decodes your cloud spend story by bringing monitoring, automation, and intelligent insights together for faster and better cloud operations.