
Traditional FinOps was built for static infrastructure. We tracked EC2 instance hours, storage GBs, and data transfer. In 2025, autonomous AI agents have broken this model. An agent is ephemeral. It spins up, consumes a variable amount of tokens across 15 different models, queries three vector databases, and then vanishes.
To manage this, we must shift from tracking Resources to tracking Outcomes. This is the new framework for Agentic FinOps.
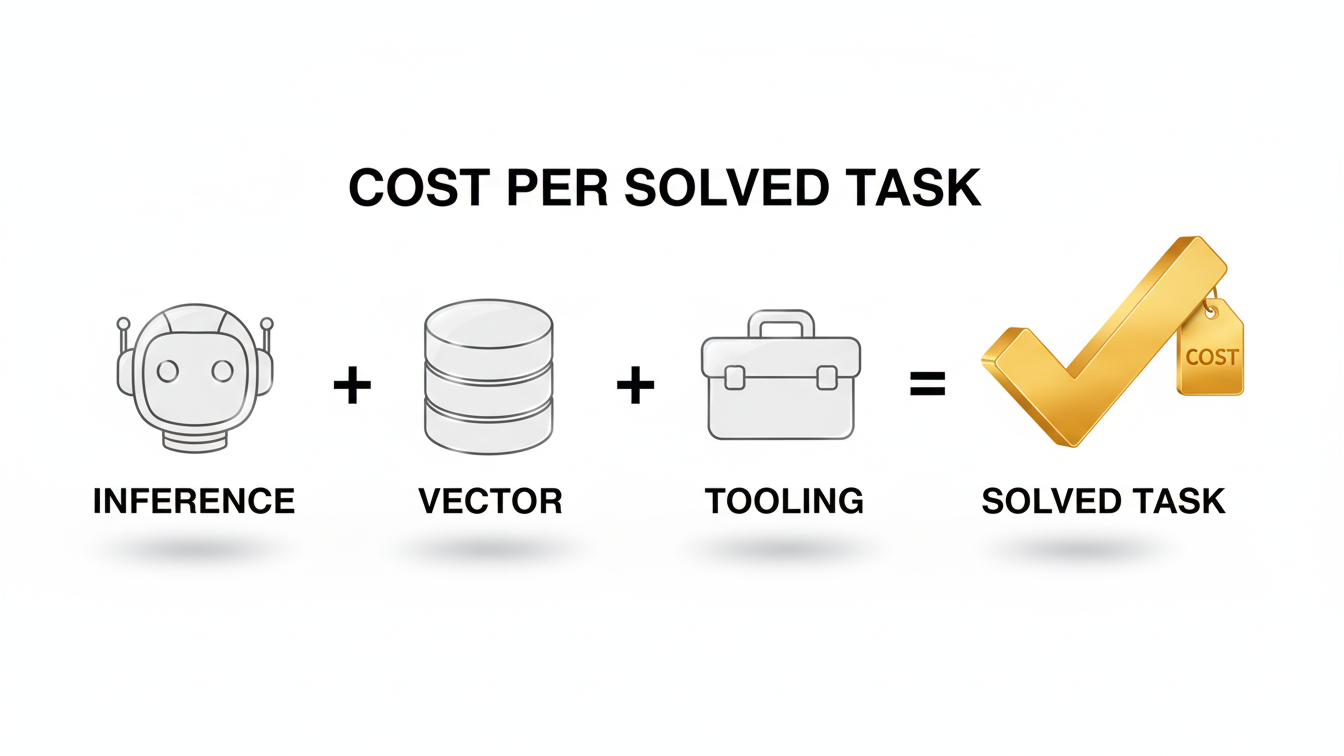
The New Metric: Cost Per Solved Task (CPST)
Stop asking "How much did we spend on OpenAI last month?" That number is useless without context. The right question is: "What is the average cost to resolve a Tier-1 Customer Support Ticket?".
The Formula:
CPST= Total Successful Tasks ∑(Inference+Vector+Tooling+Remediation)
If your agent costs $0.50 to run but fails 50% of the time, requiring a $10 human intervention, your effective CPST is $5.50. A more expensive model ($2.00) that succeeds 95% of the time yields a CPST of $2.50. Paradox: Sometimes, spending more on compute reduces the total cost.
Identity Management: The "Agent ID" Tag
In AWS or Azure, you tag resources by CostCenter. For agents, you must tag every API call with a unique Agent_Session_ID and Agent_Type.
Implementation Strategy:
Trace Propagation: Ensure your orchestration framework (LangGraph/CrewAI) generates a UUID for every task execution.
Metadata Injection: Pass this UUID as metadata in every LLM API call (using the
userorclient_idfields in OpenAI/Anthropic APIs).Tagging Infra: If the agent spins up ephemeral K8s pods or serverless functions, inject the
Agent_Session_IDas an environment variable so the cloud provider tags the compute usage.
The "Token Efficiency" Ratio
Another key health metric is the Reasoning-to-Action Ratio.
High Efficiency: Agent thinks for 1k tokens, takes an action that generates value.
Low Efficiency: Agent thinks for 20k tokens, gets confused, loops, and eventually errors out.
FinOps teams should build dashboards monitoring this ratio. A spike in the Reasoning-to-Action ratio usually indicates "Model Drift" (the agent is struggling with a new type of task) or a "Lazy Prompt" that needs engineering attention.
Conclusion
FinOps for agents requires moving up the stack. You are no longer just an accountant of infrastructure; you are an auditor of cognitive labor. If you cannot link the cloud bill to a specific business outcome, you are flying blind.
All in One Place
Atler Pilot decodes your cloud spend story by bringing monitoring, automation, and intelligent insights together for faster and better cloud operations.