
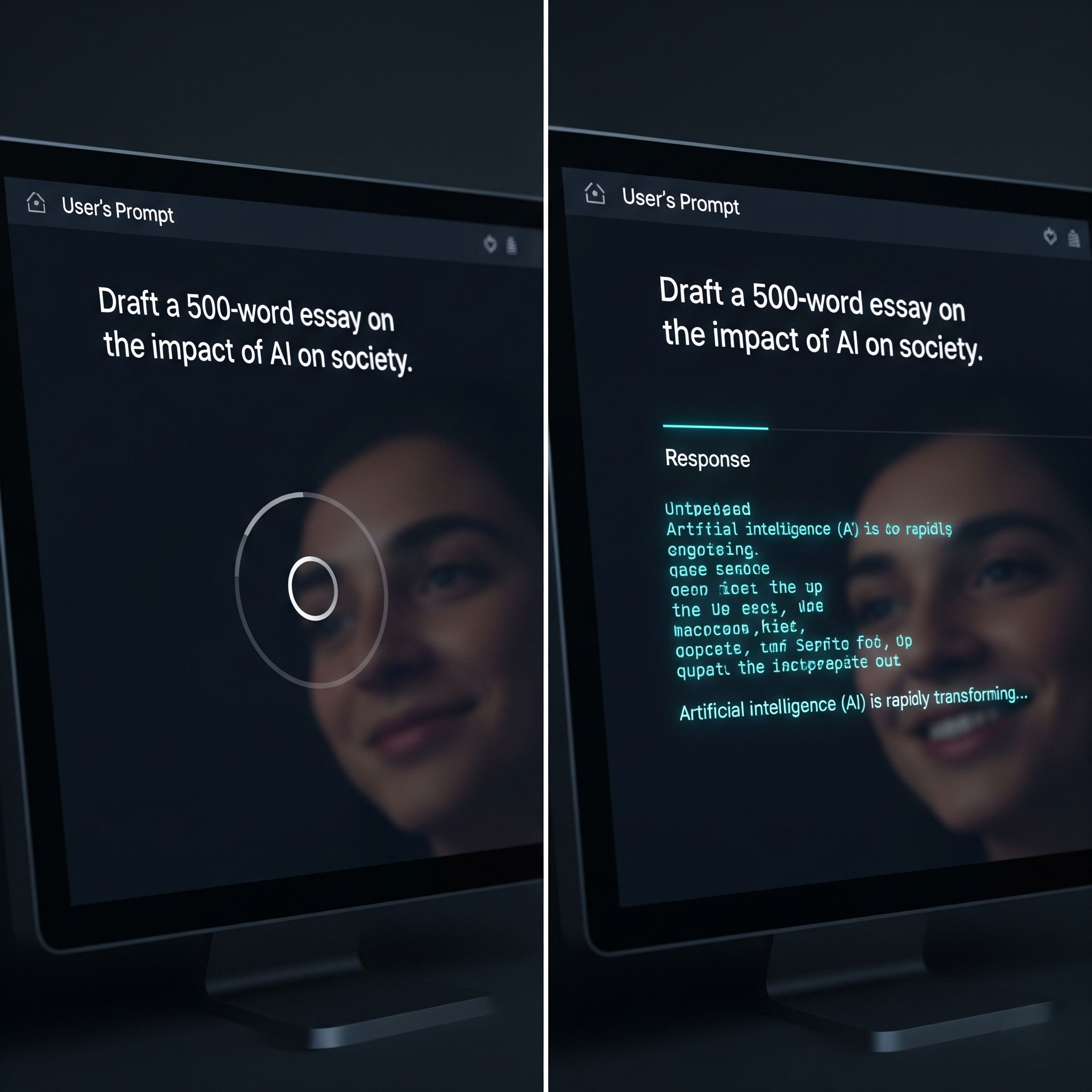
In generative AI applications, user experience is paramount. No one likes staring at a blank screen, which is why
response streaming has become the standard for chatbots. Instead of waiting for the entire response, words appear token-by-token, creating a dynamic experience that feels much faster.
This dramatic improvement in perceived performance raises a critical question: what is the
LLM response streaming cost impact? The answer is nuanced, involving a trade-off between computational resources, user perception, and provider pricing models.
How LLM Response Streaming Works
Standard (Non-Streaming) Request: You send a prompt. The model generates the entire response in memory. Once complete, it's sent back in a single chunk. The user waits for the whole process before seeing anything.
Streaming Request: You send a prompt and open a persistent connection. As the LLM generates the response one token at a time, each token is immediately sent back over this connection.
Streaming doesn't necessarily make the total generation time faster. It changes the
Time To First Token (TTFT)—the time the user waits before seeing the first piece of output. With streaming, the TTFT is very low, creating the illusion of speed.
The Cost Impact: Perception vs. Reality
The direct cost impact of streaming is not always straightforward.
Token Costs are (Usually) the Same: For most major providers, you are billed for the total number of input and output tokens processed, regardless of whether they are streamed or sent at once.
The Hidden Cost: Computational Resources: The real cost impact is on the provider's side. A streaming request requires the provider to keep a computational process and network connection active for the entire generation. This can lead to inefficient use of expensive GPU resources, especially if the model generates tokens faster than the user can read them.
The Strategic Trade-Off: User Experience vs. Cost
The decision to stream is a classic user experience vs. system efficiency trade-off.
Benefits of Streaming:
Dramatically improved perceived performance.
Increased user engagement.
Users can interrupt or re-prompt early without waiting for the full output.
Potential Downsides of Streaming:
Slightly more complex front-end implementation.
Can lead to inefficient use of the provider's resources, which could theoretically lead to higher prices or poorer service for everyone in the long run.
The Verdict: When to Stream
For the vast majority of user-facing, interactive applications, the benefits of streaming far outweigh the potential downsides.
Always Stream for: Chatbots, conversational agents, and any application where a user is waiting in real-time for a response. The improvement in user experience is non-negotiable.
Consider Not Streaming for: Asynchronous, backend processes where no user is waiting, such as a batch job to summarize 10,000 articles. A non-streaming, batched approach will likely be more efficient.
Conclusion
While the direct, per-token cost of streaming is typically the same as a standard request, the indirect cost impact is a real consideration related to computational efficiency. However, for any application that involves a human in the loop, the immense improvement in perceived performance makes streaming the clear and correct choice.
All in One Place
Atler Pilot decodes your cloud spend story by bringing monitoring, automation, and intelligent insights together for faster and better cloud operations.